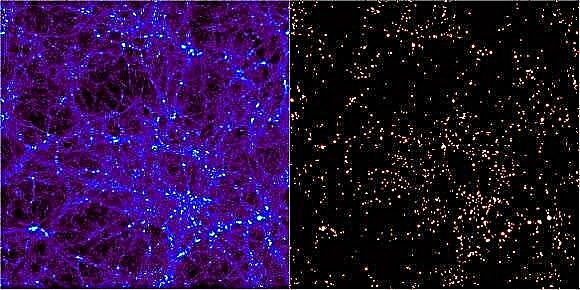
Jedným z úspechov modelu ΛCDM vesmíru je schopnosť modelov vytvárať štruktúry s mierkami a distribúciami podobnými tým, ktoré vidíme v časopise Space Magazine. Aj keď počítačové simulácie dokážu znovu vytvoriť numerické vesmíre, interpretácia týchto matematických aproximácií je sama osebe výzvou. Na identifikáciu komponentov simulovaného priestoru museli astronómovia vyvinúť nástroje na hľadanie štruktúry. Výsledkom je od roku 1974 takmer 30 nezávislých počítačových programov. Každý sľubuje odhaliť formovaciu štruktúru vo vesmíre nájdením oblastí, v ktorých sa tvoria atómy temnej hmoty. Na otestovanie týchto algoritmov bola v máji 2010 v Madride usporiadaná konferencia s názvom „Haloes going MAD“, v ktorej sa 18 z týchto kódov testovalo, aby sa zistilo, ako dobre sa zhromaždili.
Numerické simulácie vesmíru, ako napríklad slávna miléniová simulácia, začínajú iba „časticami“. Aj keď tieto boli nepochybne malé v kozmologickom meradle, také častice predstavujú kvapky tmavej hmoty s miliónmi alebo miliardami slnečných hmôt. Keď čas beží ďalej, môžu sa vzájomne ovplyvňovať podľa pravidiel, ktoré sa zhodujú s naším najlepším pochopením fyziky a povahy takejto hmoty. To vedie k vyvíjajúcemu sa vesmíru, z ktorého musia astronómovia používať zložité kódy na lokalizáciu konglomerácií temnej hmoty vo vnútri, z ktorej by sa vytvorili galaxie.
Jednou z hlavných metód, ktorú tieto programy používajú, je hľadanie malých nadmerných zaťažení a potom okolo nej pestovať sférickú škrupinu, kým hustota neklesne na zanedbateľný faktor. Väčšina z nich potom prerezá častice v objeme, ktoré nie sú gravitačne viazané, aby sa ubezpečilo, že detekčný mechanizmus sa nezachytil iba na krátkom prechodnom zhlukovaní, ktoré sa časom rozpadne. Medzi ďalšie techniky patrí hľadanie častíc vo fáze fáz pre častice s podobnou rýchlosťou všade v okolí (znamenie, že sa stali viazané).
Na porovnanie, ako sa darilo každému z týchto algoritmov, prešli dvoma testami. Prvý zahŕňal sériu zámerne vytvorených halogénov s tmavou hmotou so zabudovanými podsvetlami. Pretože distribúcia častíc bola zámerne umiestnená, výstup z programov by mal správne nájsť stred a veľkosť halogénov. Druhým testom bola úplná simulácia vesmíru. V tomto prípade by skutočná distribúcia nebola známa, ale samotná veľkosť by umožnila porovnávať rôzne programy v rovnakom súbore údajov, aby ste videli, ako podobne interpretovali spoločný zdroj.
V obidvoch testoch boli všetky nálezy všeobecne úspešné. V prvom teste sa vyskytli určité nezrovnalosti založené na tom, ako rôzne programy definovali umiestnenie halogénov. Niektorí ju definovali ako vrchol hustoty, zatiaľ čo iní ju definovali ako centrum hmoty. Pri hľadaní čiastkových halogénov sa zdalo, že tie, ktoré používali prístup vo fázovom priestore, dokázali spoľahlivejšie detekovať menšie formácie, avšak nie vždy zistili, ktoré častice v zhluku boli skutočne viazané. Pre úplnú simuláciu sa všetky algoritmy dohodli výnimočne dobre. Vzhľadom na charakter simulácie neboli malé mierky dobre zastúpené, takže porozumenie toho, ako každá z týchto štruktúr detegovala, bolo obmedzené.
Kombinácia týchto testov neuprednostňovala jeden konkrétny algoritmus alebo metódu pred iným. Ukázalo sa, že každý vo všeobecnosti dobre funguje vo vzťahu k sebe navzájom. Schopnosť toľkých nezávislých kódov s nezávislými metódami znamená, že zistenia sú mimoriadne silné. Vedomosti, ktoré odovzdávajú o tom, ako sa naše chápanie vesmíru vyvíja, umožňujú astronómom urobiť základné porovnania s pozorovateľným vesmírom, aby mohli tieto modely a teórie testovať.
Výsledky tohto testu boli zhrnuté do článku, ktorý je určený na uverejnenie v nadchádzajúcom vydaní Mesačných oznámení Kráľovskej astronomickej spoločnosti.